

When we build (web) applications, we generally think a lot about the availability and reliability of those applications. That is one of the primary reasons why the "cloud" has been so great. Recently, I was tasked to find the best way to make a Cloud Service (if you're wondering why we used Cloud Service, here's a blog post explaining it) deployment reliable. What does that mean? Well, Azure is a fairly reliable cloud system. But it had it's fair share of problems. So, most companies who will host business critical software in Azure need to have a backup plan in place. Specifically, what to do if Azure fails. Sometimes, things happen to the underlying infrastructure. And there's very little you can do about it. A couple days ago, AWS was hit with such a problem, and it affected huge customers, like Netflix, Tinder, Imdb, etc. As an interesting tid-bit, back in 2013, when something simillar happened to Amazon, there was an estimation floating around that it would cost Amazon $1000 USD PER SECOND. But more often than not, and it was also true in this case, the outage is limited to a single region.
Global Outage
If your cloud provider is suffering a global outage, you probably can't do anything about it. There are steps you can take to mitigate that though. For example, you can always abstract enough of the provider specifics to be independant. That means you are able to host your solution on either Amazon or Azure (or any other cloud provider in the world). However, that is really not cost effective. Although with Azure, you can fairly easily achieve deployment to an on-premise server as well, with very little to no dependencies to Azure. This basically helps you a lot, because almost all providers have some form of Infrastructure as a Service offerings - so if push comes to shove, you can simply spin up virutal Windows Server machines, and deploy. You need to consider things like Queues, etc., but generally those are abstracted fairly easily and fairly cheaply. Having said that, I personally would not do it in most cases. Unless your app is really really business critical, or maybe if life critical, in which case you are probably already doing this and you should be writing this post, not reading it (BTW, do comment, if you are working on such an app :-) ).
To help bring this point home, here's an excerpt from Microsoft's page:
The Azure Platform is supported by a growing network of Microsoft-managed datacenters. Microsoft has decades of experience running services such as Bing, Office 365, and outlook.com. Azure is available in 140 countries, including China, and supports 10 languages and 24 currencies, all backed by Microsoft's $15 billion (USD) investment in global datacenter infrastructure.
Trust me, if Azure is down globally, there are some heads flying, and it won't take long for it to come back up.
Localized Outage - Region Specific
While this applies to most providers, I'll limit my scope to Azure from here on out. This type of outage is more of what we, as architects and developers, can focus our attention to and do something about. Azure currently has 17 "region" datacenters. All of them are distributed across the globe - both for achieving higher performance (lower latency) as well as for achieving some redundancy in case of a catastrophic event (think earthquakes in one DC - data center). Granted, if something larger happens (large-scale mass extinction event) I think a downed DC is the last of our worries.

Source: azure.microsoft.com
When you deploy your application, either a web app, or a cloud service, you select the region in which you want your app to run. For my case, that's usually West Europe (Amsterdam) or North Europe (Ireland). So, that means that our app will be fully operational in one datacenter. And if something happens to that DC, the app is down. That "something" can affect any of the services the app uses, such as Azure Storage, SQL Azure, or the actual hosting infrastrcture.
Build it redundant
Based on all the text written above, you probably got the idea that a good way to achieve some redundancy and reliabilty, is to run the application in two different DCs. That way, if something happens to one DC, you can run the app from the other one. In general, that sounds like a good idea - all you have to do is setup your DNS servers to have a short TTL and you are good to go. If you detect the app is down, you reconfigure it, and you may be online fairly quickly - depending on how many of your crisis team members are available at that time, etc.
But let's look at how Azure will help us do that automatically, or at least semi-automatically.
Database
Most applications these days run on data. That means they connect to a data store. An example of a good data store is SQL Azure, or as we all know it, MSSQL that runs on Azure infrastructure. It's one of the most reliable parts of Azure, but they too had some issues and challenges in making that happen. Still, as we all know, database "replication", which is what we want to achieve to support the above scenario, is really hard.
SQL Azure comes with several pricing tiers, Basic, Standard and Premium. For the purpose of this blog post, we'll look at the last two. Only those two support geo-replication; the standard tier supports standard geo-replication, while the Premium tier supports active geo-replication.
Built on the same continuous copy mechanism as Active Geo-Replication, Standard Geo-Replication asynchronously replicates committed transactions from the primary database to one secondary database. The secondary, unlike Active Geo-Replication, is non-readable and does not accept client connections. It is visible on the list of secondaries and the continuous copy status can be monitored using DMVs. The non-readable secondary can be switched to active if there is a datacenter issue resulting in unavailability of the primary database.
Note that the premium tier is not called premium for no reason. It's expensive. So unless you really need active geo-replications (or the DTUs), standard should be fine.
Let's try and configure one... Basically, when you create a database within a Standard or Premium tier, and you open its dashboard, you see a big "Configure Geo-Replication" button. If you click on it, you will see a map of locations that allows you to pick the location of your replica. It recommends the best match based on DC region pairs.
[ om/content/images/2015/09/sql-3.png)
om/content/images/2015/09/sql-3.png)
Once you do that, you will see something like this:
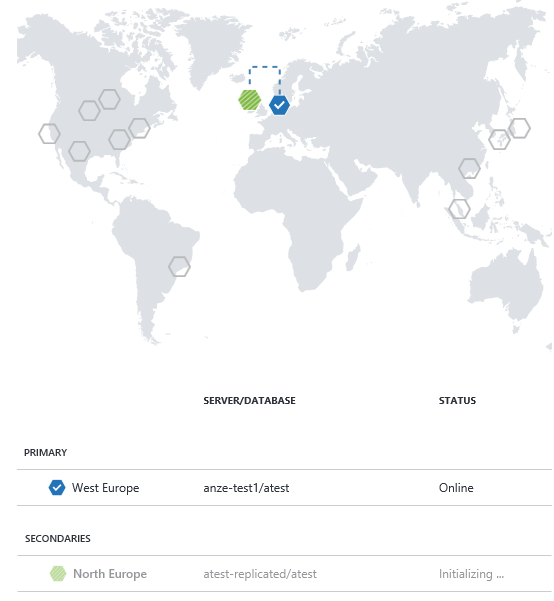 Note: you can perform this step using PowerShell as well. In general, read more about it here.
Note: you can perform this step using PowerShell as well. In general, read more about it here.
Anyway, the main idea here is that transactions are replicated to the secondary (offline) database as soon as possible, and if something happens, you get a notification in your portal, allowing you to either wait for the region to recover, or initiate the failover. You can also test this out by running DR drills.
For this to work, when you perform the failover and the secondary database transitions to being the primary one, you need to reconfigure your application to use the other database. If the application has a high-volume read-oriented workload and could benefit from read-scale load balancing in addition to fast disaster recovery** active geo-replication** is a better fit. It will basically give you a read-only copy that you can access all the time.
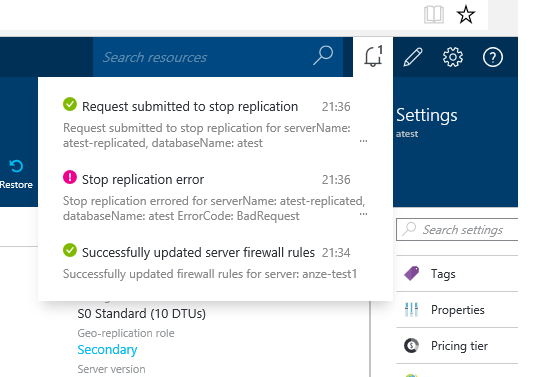
[ om/content/images/2015/09/sql-5.png)
om/content/images/2015/09/sql-5.png)
Once you do this, the database replication connection is severed, and your "secondary" database becomes an active database. Important: where it was previously billed as at a lower rate, it now starts to get billed as an active database. It's now critical, that your application is reconfigured to write to the second db or you might end up with some really strange data issues if the DC is restored at that point in time.
On a side note, if you actually try connecting to the non-readable, secondary database, you'll see this message:
[ om/content/images/2015/09/sql-no.png)
om/content/images/2015/09/sql-no.png)
This covers our data, now, let's take a look at the actual application.
Cloud Services (and Web Apps)
This same approach can actually be applied to both cloud apps and web apps. I will focus on cloud apps, because they are more relevant to my current task. But again, the approach is the same. What you need to have is a Traffic Manager configured on top of your application. The application itself, in the diagram below, is a cloud service running one web role. The Web Role needs to know how to give the Traffic Manager its status - it basically just needs to send a 200 status.
[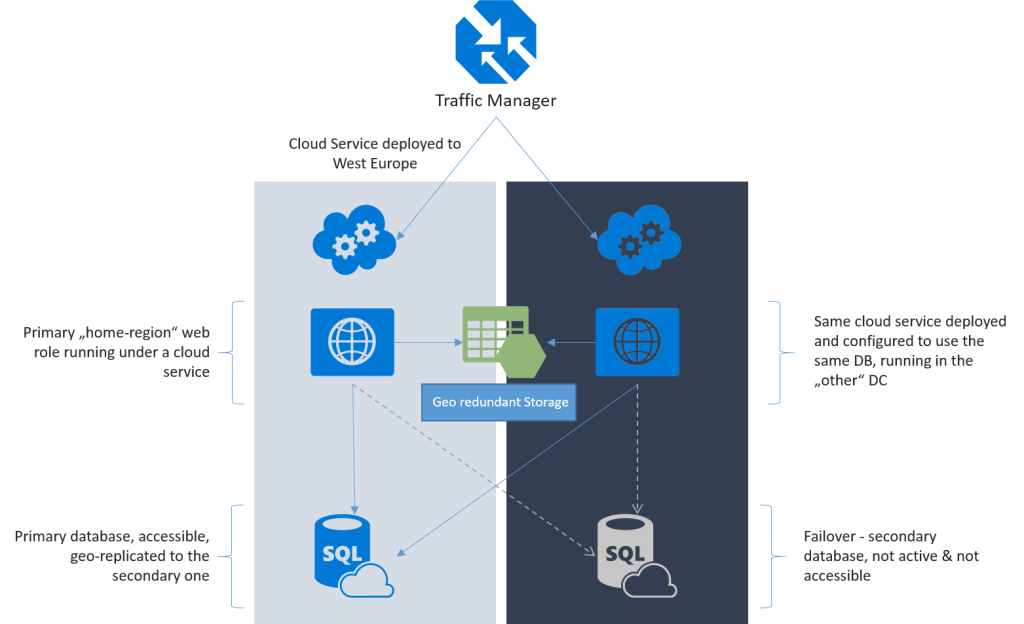 om/content/images/2015/09/tm-1.png) A high-level diagram of a "resilient" application deployment.
om/content/images/2015/09/tm-1.png) A high-level diagram of a "resilient" application deployment.
Traffic Manager can be configured in one of three ways:
- Failover - where the endpoints are in different Azure datacenters, but the primary endpoint is used to provide traffic, as long as it's available.
- Round Robin - used to distribute load across a set of endpoints, either in the same datacenter, or across different datacenters.
- Performance - calculates the "closest" datacenter for the particular request and routes it to that datacenter.
For our example, I am going to use Failover, because that is the scenario I want to test out. This means that the "backup" deployment app will be either running, scaled down to 1, or even paused until an incident occurs.
So, to test this out, I built a very simple MVC application (by built I mean clicked Create New MVC project...), and added a Status controller, which responds with an OK message and a 200 status code. This is important.
[AllowAnonymous]
public class StatusController : Controller
{
public ActionResult Index()
{
return Content("OK");
}
}
Now, in real life you would want this to be just a little bit smarter, and I'll talk about that in an upcoming blog post (Update: here it is, Monitoring the health of your (web) applications) - for example, you might want to at least return the version of your app based on the version inside your SharedAssemblyInfo.cs.
Anyway, the reason I added that Status Controller is that the Traffic Manager can be configured with a custom URL to monitor each endpoint.
I packaged the solution up, and opened the portal. Then I provisioned two separate Cloud Service Deployments, each in their own datacenter (one in North Europe, one in West Europe).
I made sure to suffix one deployment -ne (North Europe), and the other one -we (West Europe). I then waited (a long time) for the VMs to be created and verified they both responded.
Next up, Traffic Manager. I couldn't figure out a way to configure the Traffic Manager in the new portal, so I am assuming this feature is coming soon. The guys are really awesome at adding features and you can see that every couple of weeks, an update is added. The recent one, btw, was amazing.
[ om/content/images/2015/09/TrafficManager-1.png)
om/content/images/2015/09/TrafficManager-1.png)
When that's done, you can configure the endpoints. The endpoint can be either a cloud service or a web app.
[ om/content/images/2015/09/tm-endpoint-1.png)
om/content/images/2015/09/tm-endpoint-1.png)
Once you have both apps running, the Traffic Manager will report endpoint status. If one of those apps gets degraded (e.g. you stop it, or something fails), you'll see a warning, but if you open the URL associated with the Traffic Manager <name>.trafficmanager.net., you'll see the app is still runing - you can also verify that it's running on the proper location. The idea from here is, that you set your main DNS setting to point to the Traffic Manager endpoint, not the actual cloud service.
[ om/content/images/2015/09/tm-degraded.png)
om/content/images/2015/09/tm-degraded.png)
Also, as long as both endpoints are healthy, you can configure the priorities.
[ om/content/images/2015/09/tm-priorities.png)
om/content/images/2015/09/tm-priorities.png)
In the sample app, I modified the view on the actual machine to show the location (region).
[ om/content/images/2015/09/webapps.png)
om/content/images/2015/09/webapps.png)
If I now pause the North Europe deployment, when I visit my Traffic Manager URL, I'll see the normal about page. If I pause the West Europe deployment, I'll see the North Europe deployement. So it looks like it worked! And fairly seamlessly at that. The benefit is that the price of this solution is acceptable. You basically need to factor in the cost of another cloud instance (but you can keep it in a Warm-Spare sort of state), and the cost of the Traffic Manager which is billed based on DNS requests (€0.4554 per first million queries, €0.3163 per million next queries).
A note on Storage Accounts (Blobs, Queues, etc.)
In the current pricing strategy, you can select a pricing plan that includes Geo replicated storage. You can again choose what type of redundancy you would like to have, so for example you can have read-access geo-redundant storage, or fully geo-redundant. But, the best part is that for this technology, Azure will handle failover automatically. As per this blog, the failover occurs through a DNS change. So once that's propagated, your app should continue to work normally. For more information on different types of redundancy available for storage accounts, please read this.
[ om/content/images/2015/09/geo-1.png)
om/content/images/2015/09/geo-1.png)
Summary
All in all, Azure provides a really good and cost-efficient way to build reliable apps and to ensure business continuity. I've set out to write a short summary of how this could look like in practice, for a cloud service app. Of course, as architects always will tell you, the end solution depends on your problem. So, in your specific case, you might be better off doing something else. But, you can always reach out to me, and we can talk about it. Maybe I can help you solve this, or another, related problem?