
In a recent post on Medium, I wrote: "Every production project needs a way to track bugs. Most will be able to then track the problems down to a specific area, and the most advanced teams will be able to figure out if a bug is specific to a changeset. For example, in our team, we have a way of doing that". It still amazed me how come** this is not the first thing developers do** when they start a project. After all, Continuous Integration has been around for a while now. In fact, tt was first named and proposed by Grady Booch in his 1991 method (source: Wikipedia).
A bit of background
Even for our team, it took a long time, to make both our projects fully automated. At the moment, we have three projects:
- A WPF-based Point of Sale application (deployed via ClickOnce),
- its back-end application, based on MVC and running on Azure App Service
- a single-sign-on solution for the entire range of products across the company (User Account).
While all three are related (the back-end, obviously, uses the single-sign-on functionality of our User Account system), the first two are more closely intertwined. They represent a connected system - this is important information because we need to know that certain versions function with each other.
Unfortunately, due to some specifics, our build is not a single step process. That means we actually need to run a script before we go on and do the build using msbuild. Well, to be honest, we only need to do that once. The script does a little bit of manipulation to the configuration files, allowing us to have multiple different testing environments (local, QA, dev staging, staging, production...). And while we are being honest, the script actually does not affect the build per-se. The solution still builds.
The Infrastructure
We are actually running on two different infrastructure setups. On that note, we worked with the Ognjen Bajič, from Ekobit who have helped us tremendously. Unfortunately, the infrastructure migration is not complete yet, but we are planning to getting back to that.
One part (the legacy things, User Account & all other products) runs on an older Team Foundation Server, whereas the new POS and the backend system are hosted & built on**Visual Studio Online**. In case you don't know, it is basically a hosted Team Foundation Server, managed by Microsoft, allowing you to skirt a lot of issues that you had when you set it up locally. A licence to use it is also included in each MSDN subscription, which means most companies (partners at silver level, if I am not mistaken) have it covered.
Additionally, we have a couple locally hosted build machines. These machines are Windows 8 workstations (and some legacy versions for other products that are not relevant to this discussion). They are local because:
- running build online costs money, we did not want to spend,
- we have the required infrastructure setup locally (Hyper-V server, with lots of RAM and a proper SAN setup),
- we need additional dependencies installed on the machine (a couple SDKs) that are build-time requirements.
At the moment, as far as I know, the hosted build controllers do not support third-party SDKs, but Microsoft thought of that, so you can connect a TFS Build Agent to Visual Studio Online.
Making it all work
That is the hard part. Thankfully, Microsoft built a new Scriptable Build System, a short while ago. It actually made implementing our process much much easier.
What process, I hear you asking?
Continuous Integration (CI) roughly means that every team member keeps_ continuously integrating_ their changes to the main source repository and that source is then immediately built (and ideally tested). Further, a lot of companies are now practising Continuous Deployment (CD) which is taking CI one step further and also deploying the source code to the right environment. For CD to function, you need to automate the deployment process (duh).
In our case that meant the following:
-
The WPF Point of Sale
- Publishing the ClickOnce package into a drop*
- Deploying the drop to the file host server we use for dissemination of the product (in the right order).
-
The Web Backend
- Publishing a "Web Deploy Package" into a drop
- Deploying the drop to the Azure Website deployment (local, QA or dev staging)
* I promise I will write a blog post about this. When I did this, I had so many questions and problems, it was ridiculous.
The Web part is the easiest. More or less. Thankfully, Microsoft already has us covered with a sample template.
However, in our case, we actually needed to do a bit of modifications to have the drop folder also accessible. In our environment, we are not allowed to touch (real) staging and production servers, as is expected and normal. If your team has access to those servers, and you are a developer, raise hell. I know it goes against all the grains in our developer bodies, but you really should not be deploying (your complex, business app) to production. If you are building a website, there is less harm there, but still be careful.
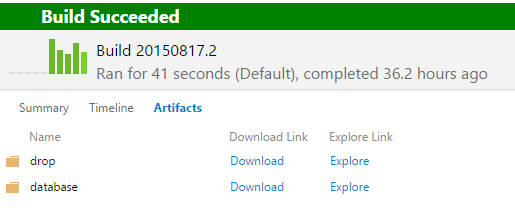
On a side note, the web project also produces a folder with Database migration scripts. We have both of those artefacts available for download when the build completes.
Tracking Issues to Changesets
That is all fine and dandy, but how do we know what change in our source caused a bug? Well, for starters, the requisite for that is that you have a QA department. Ideally, you would also have automated tests that are executed at certain points (as often as possible, but that it is still not hogging down your server and CI process - e.g. no use in doing it on every check-in if it takes 1 hour to run the tests). In any case, manually or automatically you execute a set of tests that show you if something is broken. Because you are building and storing the artefacts for the builds, if you miss something, QA can go back and retroactively test certain versions (bisection, anyone?) to figure out when an issue started occurring.
But that also requires that you know which build produced the version that the client (or server) is running. To do that, we sync our version (in the AssemblyInfo.cs file) with the build number.
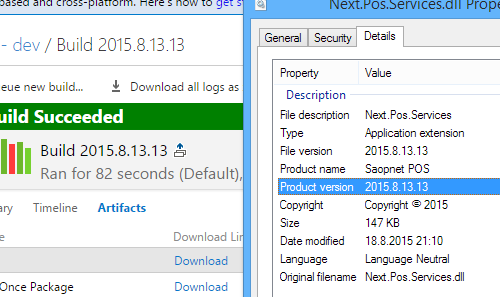
To accomplish this, we use a variation of this script: https://github.com/cfbarbero/TFSBuild/blob/master/ApplyVersionToAssemblies.ps1. In addition, we also use a proper SharedAssemblyInfo.cs to do that.
The file basically has the following code:
using System.Reflection;
using System.Resources;
using System.Runtime.InteropServices;
[assembly: AssemblyConfiguration("")]
[assembly: AssemblyCompany("Company")]
[assembly: AssemblyProduct("product")]
[assembly: AssemblyCopyright("Copyright © 2015")]
[assembly: AssemblyTrademark("trademark")]
[assembly: NeutralResourcesLanguage("sl-SI")]
[assembly: ComVisible(false)]
// DO NOT change the version. It is updated automatically during the build
// process, and is linked with the build number & type.
[assembly: AssemblyVersion("0.0.0.0")]
We have this file in the Properties folder of our main, infrastructure projects that is used by all other projects in the solution We do this so that each DLL will have the version, not just one - making really sure we don't load something we do not want to.
From there on, it takes a bit of manual work in each .csproj file, but we add the following lines of code in it:
<Compile Include="..\Infrastructure\Properties\SharedAssemblyInfo.cs">
<Link>Properties\SharedAssemblyInfo.cs</Link>
</Compile>
In conclusion...
If you look at your process, and consider what I wrote above, you should be able to identify which changes broke something in the actual application. But, an added benefit of it all, is also that your deployment process will function more smoothly, and you, as a developer, will be fairly certain that code can be built (CI) and even better, that there will be no last-minute-panic moments when you are deploying it (CD).
Are you doing something better? Do you have any similar experiences? I'd love to heart about it!



