Very often, when developers start learning a new technology (for example, ASP.NET), we do not take the time to properly structure the code. That is of course perfectly OK... However, as we progress in our career, it makes sense to understand better how to structure the code. There are various architectural patterns that govern structuring of code, but none are as fundamental as the basic pattern of layering the code. And the Repository and Services pattern are really nothing but patterns for layering (in addition to everything else) or structuring the code.
The wide-spread usage of the MVC and MVVM patterns (and respected frameworks) helped ensure that most developers already understand that writing code that accesses the database on the UI is almost always a bad idea. Why almost? Well, as with everything else in architecture, the proper answer is "it depends". It depends on various factors, including reusability requirement, timelines, etc. If you have a really simple application, that does nothing but displays some data from a table it would be a waste of time and effort to use (an) MVC (framework) when a simple WebForms application would probably do the trick.
However, we are talking about more complex applications, usually full of business/domain logic, and often lots of interacting components that may or may not be located on different servers/locations/containers. The basic idea then, is to group common code together.
In my post about MVC, I talked about the role of the controller to be "the link between the user and the system". That means that it takes user input, and then communicates with business logic to perform actions and tasks, results of which are then displayed back to the user.
In smaller applications, the "business logic" is so simple, and small, that it fits perfectly inside the controller. There is really no need to move it anywhere else. However, as our application grows, or rather, as the business rules governing it grow, we start to separate the code further. The basic idea, with layered architecture, is to "layer" the code:
- Presentation Layer (User Interface)
- Service Layer (if needed)
- Business Layer
- Data Access Layer
Be careful when adding additional layers, and do not add them if they do not provide a logical grouping of related components that manifestly increases the maintainability, scalability, or flexibility of your application. For example, if your application does not expose services, a separate service layer may not be required and you may just have presentation, business, and data access layers.
https://msdn.microsoft.com/en-us/library/ee658109.aspx
In my architectures, for smaller applications, I tend to call my Business Logic containers Services. In reality, if you consult the diagram by Microsoft, the business logic would be implemented in a separate layer, but, again, for smaller applications, that is not really needed.
 Source: Microsoft
Source: Microsoft
So, while in a larger application (think bigger enterprise apps), we would actually separate the service interfaces away from the logic (e.g. workflows, and business entities), we can afford to couple them here.
So what goes in a service?
The simple, and most correct answer is, it depends. Well, my initial response to this is a very pragmatic one. I usually say: "If it has an If, there is a big chance it's business logic - service material". Obviously, this is a very strange statement. After all, most programming code has a couple if statements in there... However, the basic gist of it boils down to the fact that if the code has any logic about the underlying domain of the application; about the actual business problem it is solving, that most certainly is business layer material.
Looking at my architecture and code base, I usually make the models really dumb. Basically, all the models are are POCOs. There was a time in my architecture, and I still do this often, that I had the POCOs auto-generated (T4) and flowed to the UI layer itself - then encapsulated in the View Model, if required. That means that the logic of doing "important" stuff then goes to the service.
Let's take a look at a classic service method:
public long Activate(Guid token)
{
// get the user registration
var dbProspect = _userRegistrationRepository.Get(x => x.Token == token);
Ensure.ArgumentNotNull(dbProspect, "Prospect user");
// get the user's location
var dbLocation = _locationRepository.Get(x => x.LocationId == dbProspect.LocationId);
Ensure.ArgumentNotNull(dbLocation, "Location");
// we will now create the user
var dbUser = new User()
{
DateTimeCreated = DateTime.UtcNow,
Email = dbProspect.Email,
FirstName = dbProspect.FirstName,
LastName = dbProspect.LastName,
Username = dbProspect.Email,
LocationId = dbLocation.LocationId,
TimeZoneId = dbLocation.TimeZoneId,
Realm = dbProspect.Realm
};
dbUser = _userRepository.Add(dbUser);
_userRegistrationRepository.Delete(dbProspect);
return dbUser.UserId;
}
This method completes the user registration - when the user registers, a prospect is created, a confirmation email is sent to the provided email address, and only when the user confirms the email, do we actually go on an create the user principal object. This method is located in IRegistrationService. Through Dependency Injection, we call the actual concrete implemention from our Controller.
While this specific method is fairly light on actual business logic it gives a fairly good idea of the approach. We get the data from a source (here's where the repository comes in), and we execute our business logic over that data.
And the Repository?
Well, the Repository in my case, is an abstraction on top of the data Access layer.
A long time, while still at an agency, we wrote a little T4 script that auto-generates generic repositories (I can hear people cringing at the thought of this :-)). But, it worked for us, and we were able to implement features really quickly and efficiently. The learning time was also really small, so new developers quickly understood how and what we were doing. Granted, it had a couple problems - most notably, the idea of bringing in a [Unit of Work](http://Unit of Work) pattern was implausible.
Here's one example (used above, as well) of such an auto-generated repository:
//------------------------------------------------------------------------------
// <auto-generated>
// This code was generated from a template.
//
// Changes to this file may cause incorrect behavior and will be lost if
// the code is regenerated.
// </auto-generated>
//------------------------------------------------------------------------------
namespace DirectoryServices.Repositories {
public partial class UserRegistrationRepository : TransactionAwareRepository, IUserRegistrationRepository {
protected readonly DirectoryServicesEntities _entities;
public UserRegistrationRepository(DirectoryServicesEntities entities) : base(entities) {
_entities = entities;
}
public virtual UserRegistration Add(UserRegistration entity) {
_entities.UserRegistrations.Add(entity);
_entities.SaveChanges();
return entity;
}
public virtual IQueryable<UserRegistration> Entities {
get {
return _entities.UserRegistrations;
}
}
public virtual IQueryable<UserRegistration> NonCachedEntities {
get {
return _entities.UserRegistrations.AsNoTracking();
}
}
public virtual UserRegistration Get(System.Linq.Expressions.Expression<Func<UserRegistration, bool>> predicate) {
return Entities.SingleOrDefault(predicate);
}
public virtual UserRegistration Update(UserRegistration entity) {
_entities.SaveChanges();
return entity;
}
public virtual void Delete(UserRegistration entity) {
_entities.UserRegistrations.Remove(entity);
_entities.SaveChanges();
}
public virtual void Delete(System.Linq.Expressions.Expression<Func<UserRegistration, bool>> predicate)
{
var range = _entities.UserRegistrations.Where(predicate);
_entities.UserRegistrations.RemoveRange(range);
_entities.SaveChanges();
}
}
}
Keep in mind though, a Repository, by definition "m__ediates between the domain and data mapping layers using a collection-like interface for accessing domain objects". That's what we did. We exposed a collection like interface for accessing the objects - but they weren't really domain objects. The one thing our repository accomplishes though, is that it generally does not imply that all callers need to reference Entity Framework. The idea behind this was that we wanted to have a fairly generic service layer.
In all honesty, that's a bad idea in retrospect. But it still did the trick.
There is one good thing that comes from using repositories, it helps you separate concerns cleanly:
- the data comes from the repository (it Will handle going to the store)
- the data is processed at the business logic layer (service)
Note that the data in question does not necessarily have to come from a database and the logic still applies. For example, we have an ILoggingRepository that is passed into our implementation of the ILoggingService. The repository writes to an external service (using a Gateway and the Circuit Breaker patterns underneath). We also have some other services and repositores that read data from Table Storage, Queues, etc., all of which can be abstracted into a Repository.
Why go through all this trouble?
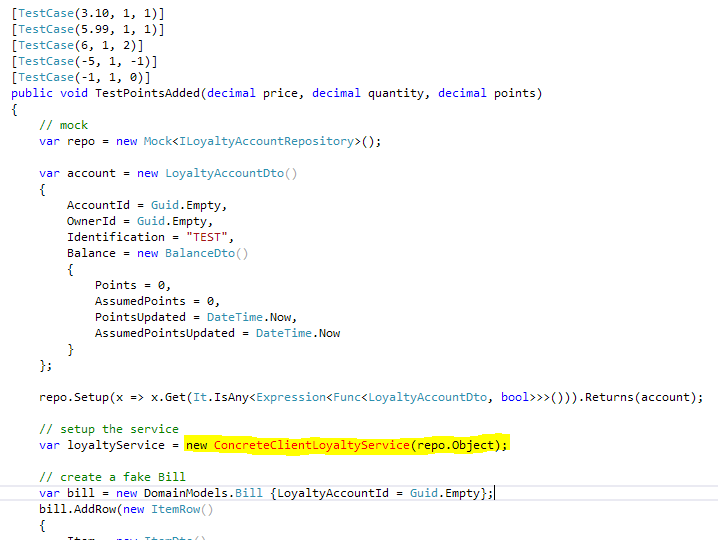
Well, the primary benefit of this decoupling is that your code becomes much more testable. You can now mock your service & repository objects, and test your controller and further on, service implementations.
In the following example (sorry, it's an image...), you can see that we actually mock a repository object and pass it to a concrete implementation of a service. We then make sure the proper methods are called.